Newton's Method for Constrained Optimization (BV Chapters 10, 11)¶
We only consider convex optimization in this lecture.
Equality constraint¶
- Consider equality constrained optimization \begin{eqnarray*} &\text{minimize}& f(\mathbf{x}) \\ &\text{subject to}& \mathbf{A} \mathbf{x} = \mathbf{b}, \end{eqnarray*} where $f$ is convex.
KKT condition¶
The Langrangian function is \begin{eqnarray*} L(\mathbf{x}, \lambda) = f(\mathbf{x}) + \nu^T(\mathbf{A} \mathbf{x} - \mathbf{b}), \end{eqnarray*} where $\nu$ is the vector of Langrange multipliers.
Setting the gradient of Langrangian function to zero yields the optimality condition (Karush-Kuhn-Tucker condition) \begin{eqnarray*} \mathbf{A} \mathbf{x}^\star &=& \mathbf{b} \quad \quad (\text{primal feasibility condition}) \\ \nabla f(\mathbf{x}^\star) + \mathbf{A}^T \nu^\star &=& \mathbf{0} \quad \quad (\text{dual feasibility condition}) \end{eqnarray*}
Newton algorithm¶
Let $\mathbf{x}$ be a feasible point, i.e., $\mathbf{A} \mathbf{x} = \mathbf{b}$, and denote Newton direction by $\Delta \mathbf{x}$. By second order Taylor expansion \begin{eqnarray*} f(\mathbf{x} + \Delta \mathbf{x}) \approx f(\mathbf{x}) + \nabla f(\mathbf{x})^T \Delta \mathbf{x} + \frac 12 \Delta \mathbf{x}^T \nabla^2 f(\mathbf{x}) \Delta \mathbf{x}. \end{eqnarray*} To maximize the quadratic approximation subject to constraint $\mathbf{A}(\mathbf{x} + \Delta \mathbf{x}) = \mathbf{b}$, we solve the KKT equation \begin{eqnarray*} \begin{pmatrix} \nabla^2 f(\mathbf{x}) & \mathbf{A}^T \\ \mathbf{A} & \mathbf{0} \end{pmatrix} \begin{pmatrix} \Delta \mathbf{x} \\ \nu \end{pmatrix} = \begin{pmatrix}
- \nabla f(\mathbf{x}) \ \mathbf{0} \end{pmatrix} \end{eqnarray*} for the Newton direction.
When $\nabla^2 f(\mathbf{x})$ is pd and $\mathbf{A}$ has full row rank, the KKT matrix is nonsingular therefore the Newton direction is uniquely determined.
Line search is similar to the unconstrained case.
Infeasible Newton step. So far we assume that we start with a feasible point. How to derive Newton step from an infeasible point $\mathbf{x}$? Again from the KKT condition, \begin{eqnarray*} \begin{pmatrix} \nabla^2 f(\mathbf{x}) & \mathbf{A}^T \\ \mathbf{A} & \mathbf{0} \end{pmatrix} \begin{pmatrix} \Delta \mathbf{x} \\ \omega \end{pmatrix} = - \begin{pmatrix} \nabla f(\mathbf{x}) \\ \mathbf{A} \mathbf{x} - \mathbf{b} \end{pmatrix}. \end{eqnarray*} Writing the updated dual variable $\omega = \nu + \Delta \nu$, we have the equivalent form in terms of primal update $\Delta \mathbf{x}$ and dual update $\Delta \nu$ \begin{eqnarray*} \begin{pmatrix} \nabla^2 f(\mathbf{x}) & \mathbf{A}^T \\ \mathbf{A} & \mathbf{0} \end{pmatrix} \begin{pmatrix} \Delta \mathbf{x} \\ \Delta \nu \end{pmatrix} = - \begin{pmatrix} \nabla f(\mathbf{x}) + \mathbf{A}^T \nu \\ \mathbf{A} \mathbf{x} - \mathbf{b} \end{pmatrix}. \end{eqnarray*} The righthand side is recognized as the primal and dual residuals. Therefore the infeasible Newton step is also interpreted as a primal-dual mtehod.
It can be shown that the norm of the residual decreases along the Newton direction. Therefore line search is based on the norm of residual.
Inequality constraint - interior point method¶
We consider the constrained optimization \begin{eqnarray*} &\text{minimize}& f_0(\mathbf{x}) \\ &\text{subject to}& f_i(\mathbf{x}) \le 0, \quad i = 1,\ldots,m \\ & & \mathbf{A} \mathbf{x} = \mathbf{b}, \end{eqnarray*} where $f_0, \ldots, f_m: \mathbb{R}^n \mapsto \mathbb{R}$ are convex and and twice continuously differentiable, and $\mathbf{A}$ has full row rank.
We assume the problem is solvable with optimal point $\mathbf{x}^\star$ and and optimal value $f_0(\mathbf{x}^\star) = p^\star$.
KKT condition: \begin{eqnarray*} \mathbf{A} \mathbf{x}^\star = \mathbf{b}, f_i(\mathbf{x}^\star) &\le& 0, i = 1,\ldots,m \quad (\text{primal feasibility}) \\ \lambda^\star &\succeq& \mathbf{0} \\ \nabla f_0(\mathbf{x}^\star) + \sum_{i=1}^m \lambda_i^\star \nabla f_i(\mathbf{x}^\star) + \mathbf{A}^T \nu^\star &=& \mathbf{0} \quad \quad \quad \quad \quad \quad (\text{dual feasibility}) \\ \lambda_i^\star f_i(\mathbf{x}^\star) &=& 0, \quad i = 1,\ldots,m. \end{eqnarray*}
Barrier method¶
Alternative form makes inequality constraints implicit in the objective \begin{eqnarray*} &\text{minimize}& f_0(\mathbf{x}) + \sum_{i=1}^m I_-(f_i(\mathbf{x})) \\ &\text{subject to}& \mathbf{A} \mathbf{x} = \mathbf{b}, \end{eqnarray*} where \begin{eqnarray*} I_-(u) = \begin{cases} 0 & u \le 0 \\ \infty & u > 0 \end{cases}. \end{eqnarray*}
The idea of the barrier method is to approximate $I_-$ by a differentiable function \begin{eqnarray*} \hat I_-(u) = - (1/t) \log (-u), \quad u < 0, \end{eqnarray*} where $t>0$ is a parameter tuning the approximation accuracy. As $t$ increases, the approximation becomes more accurate.
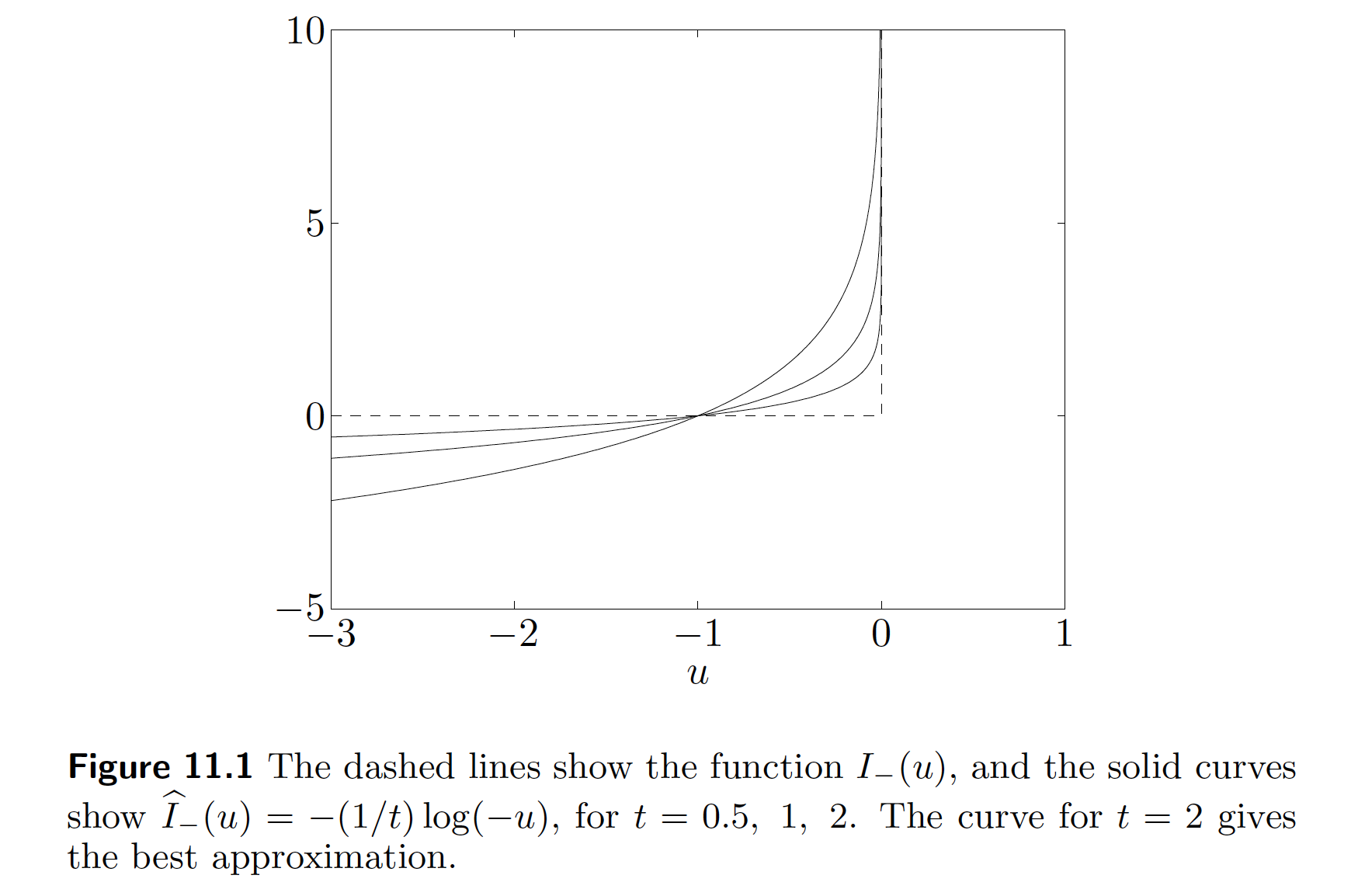
The barrier method solves a sequence of equality-constraint problems \begin{eqnarray*} &\text{minimize}& t f_0(\mathbf{x}) - \sum_{i=1}^m \log(-f_i(\mathbf{x})) \\ &\text{subject to}& \mathbf{A} \mathbf{x} = \mathbf{b}, \end{eqnarray*} increasing the parameter $t$ at each step and starting each Newton minimization at the solution for the previous value of $t$.
The function $\phi(\mathbf{x}) = - \sum_{i=1}^m \log (-f_i(\mathbf{x}))$ is called the logarithmic barrier or log barrier function.
Denote the solution at $t$ by $\mathbf{x}^\star(t)$. Using duality theory, it can be shown \begin{eqnarray*} f_0(\mathbf{x}^\star(t)) - p^\star \le m / t. \end{eqnarray*}
- Feasibility and phase I methods. Barrier method has to start from a strictly feasible point. We can find such a point by solving \begin{eqnarray*} &\text{minimize}& s \\ &\text{subject to}& f_i(\mathbf{x}) \le s, \quad i = 1,\ldots,m \\ & & \mathbf{A} \mathbf{x} = \mathbf{b} \end{eqnarray*} by the barrier method.
Primal-dual interior-point method¶
Difference from barrier method: no double loop.
In the barrier method, it can be show that a point $\mathbf{x}$ is equal to $\mathbf{x}^\star(t)$ if and only if
\begin{eqnarray*} \nabla f0(\mathbf{x}) + \sum{i=1}^m \lambda_i \nabla f_i(\mathbf{x}) + \mathbf{A}^T \nu &=& \mathbf{0} \- \lambda_i f_i(\mathbf{x}) &=& 1/t, \quad i = 1,\ldots,m \ \mathbf{A} \mathbf{x} &=& \mathbf{b}. \end{eqnarray*}
We define the KKT residual
\begin{eqnarray*} r_t(\mathbf{x}, \lambda, \nu) = \begin{pmatrix} \nabla f_0(\mathbf{x}) + Df(\mathbf{x})^T \lambda + \mathbf{A}^T \nu \- \text{diag}(\lambda) f(\mathbf{x}) - (1/t) \mathbf{1} \ \mathbf{A} \mathbf{x} - \mathbf{b} \end{pmatrix} \triangleq \begin{pmatrix} r_{\text{dual}} \\ r_{\text{cent}} \\ r_{\text{pri}} \end{pmatrix}, \end{eqnarray} where \begin{eqnarray} f(\mathbf{x}) = \begin{pmatrix} f_1(\mathbf{x}) \\ \vdots \\ f_m(\mathbf{x}) \end{pmatrix}, \quad Df(\mathbf{x}) = \begin{pmatrix} \nabla f_1(\mathbf{x})^T \\ \vdots \\ \nabla f_m(\mathbf{x})^T \end{pmatrix}. \end{eqnarray*}
Denote the current point and Newton step as
\begin{eqnarray*} \mathbf{y} = (\mathbf{x}, \lambda, \nu), \quad \Delta \mathbf{y} = (\Delta \mathbf{x}, \Delta \lambda, \Delta \nu). \end{eqnarray*} In view of the linear equation \begin{eqnarray*} r_t(\mathbf{y} + \Delta \mathbf{y}) \approx r_t(\mathbf{y}) + Dr_t(\mathbf{y}) \Delta \mathbf{y} = \mathbf{0}, \end{eqnarray*} we solve $\Delta \mathbf{y} = - D r_t(\mathbf{y})^{-1} r_t(\mathbf{y})$, i.e., \begin{eqnarray*} \begin{pmatrix} \nabla^2 f0(\mathbf{x}) + \sum{i=1}^m \lambda_i \nabla^2 f_i(\mathbf{x}) & Df(\mathbf{x})^T & \mathbf{A}^T \- \text{diag}(\lambda) Df(\mathbf{x}) & - \text{diag}(f(\mathbf{x})) & \mathbf{0} \ \mathbf{A} & \mathbf{0} & \mathbf{0} \end{pmatrix} \begin{pmatrix} \Delta \mathbf{x} \\ \Delta \lambda \\ \Delta \nu \end{pmatrix} = - \begin{pmatrix} r_{\text{dual}} \\ r_{\text{cent}} \\ r_{\text{pri}} \end{pmatrix} \end{eqnarray*} for the primal-dual search direction.