Optimization Examples - Quadratic Programming¶
Quadratic programming (QP)¶
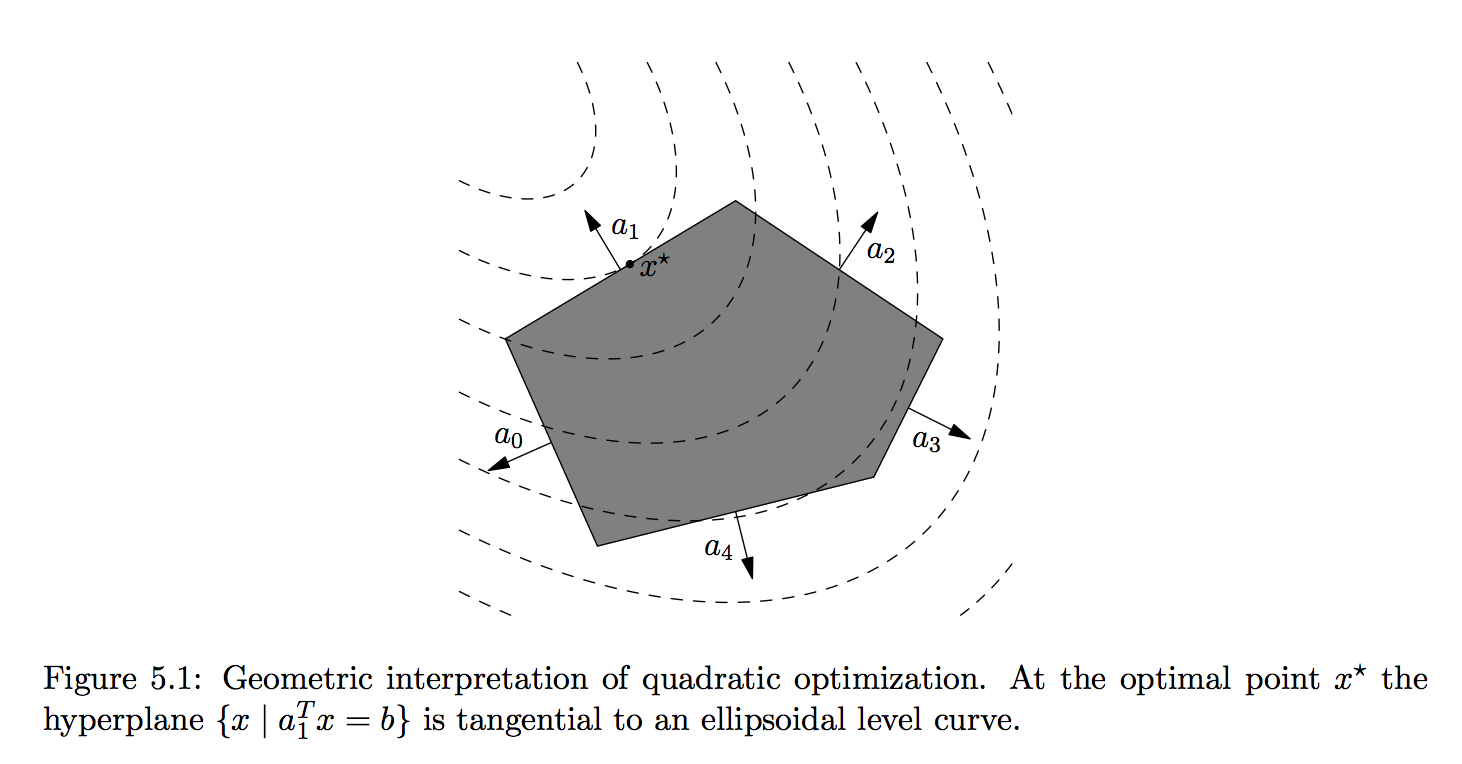
- A quadratic program (QP) has quadratic objective function and affine constraint functions \begin{eqnarray*} &\text{minimize}& (1/2) \mathbf{x}^T \mathbf{P} \mathbf{x} + \mathbf{q}^T \mathbf{x} + r \\ &\text{subject to}& \mathbf{G} \mathbf{x} \preceq \mathbf{h} \\ & & \mathbf{A} \mathbf{x} = \mathbf{b}, \end{eqnarray*} where we require $\mathbf{P} \in \mathbf{S}_+^n$ (why?). Apparently LP is a special case of QP with $\mathbf{P} = \mathbf{0}_{n \times n}$.
Examples¶
Example. The least squares problem minimizes $\|\mathbf{y} - \mathbf{X} \beta\|_2^2$, which obviously is a QP.
Example. Least squares with linear constraints. For example, nonnegative least squares (NNLS) \begin{eqnarray*} &\text{minimize}& \frac 12 \|\mathbf{y} - \mathbf{X} \beta\|_2^2 \\ &\text{subject to}& \beta \succeq \mathbf{0}. \end{eqnarray*}
In NNMF (nonnegative matrix factorization), the objective $\|\mathbf{X} - \mathbf{V} \mathbf{W}\|_{\text{F}}^2$ can be minimized by alternating NNLS.
Example. Lasso regression Tibshirani (1996), Donoho (1994) minimizes the least squares loss with $\ell_1$ (lasso) penalty \begin{eqnarray*} &\text{minimize}& \frac 12 \|\mathbf{y} - \beta_0 \mathbf{1} - \mathbf{X} \beta\|_2^2 + \lambda \|\beta\|_1, \end{eqnarray*} where $\lambda \ge 0$ is a tuning parameter. Writing $\beta = \beta^+ - \beta^-$, the equivalent QP is \begin{eqnarray*} &\text{minimize}& \frac 12 (\beta^+ - \beta^-)^T \mathbf{X}^T \left(\mathbf{I} - \frac{\mathbf{1} \mathbf{1}^T}{n} \right) \mathbf{X} (\beta^+ - \beta^-) + \\ & & \quad \mathbf{y}^T \left(\mathbf{I} - \frac{\mathbf{1} \mathbf{1}^T}{n} \right) \mathbf{X} (\beta^+ - \beta^-) + \lambda \mathbf{1}^T (\beta^+ + \beta^-) \\ &\text{subject to}& \beta^+ \succeq \mathbf{0}, \, \beta^- \succeq \mathbf{0} \end{eqnarray*} in $\beta^+$ and $\beta^-$.


Example: Elastic net Zou and Hastie (2005) \begin{eqnarray*} &\text{minimize}& \frac 12 \|\mathbf{y} - \beta_0 \mathbf{1} - \mathbf{X} \beta\|_2^2 + \lambda (\alpha \|\beta\|_1 + (1-\alpha) \|\beta\|_2^2), \end{eqnarray*} where $\lambda \ge 0$ and $\alpha \in [0,1]$ are tuning parameters.
Example: Image denoising by anisotropic penalty. See http://hua-zhou.github.io/teaching/st790-2015spr/ST790-2015-HW5.pdf.
Example: (Linearly) constrained lasso \begin{eqnarray*} &\text{minimize}& \frac 12 \|\mathbf{y} - \beta_0 \mathbf{1} - \mathbf{X} \beta\|_2^2 + \lambda \|\beta\|_1 \\ &\text{subject to}& \mathbf{G} \beta \preceq \mathbf{h} \\ & & \mathbf{A} \beta = \mathbf{b}, \end{eqnarray*} where $\lambda \ge 0$ is a tuning parameter.
Example: The Huber loss function \begin{eqnarray*} \phi(r) = \begin{cases} r^2 & |r| \le M \\ M(2|r| - M) & |r| > M \end{cases} \end{eqnarray*} is commonly used in robust statistics. The robust regression problem \begin{eqnarray*} &\text{minimize}& \sum_{i=1}^n \phi(y_i - \beta_0 - \mathbf{x}_i^T \beta) \end{eqnarray*} can be transformed to a QP \begin{eqnarray*} &\text{minimize}& \mathbf{u}^T \mathbf{u} + 2 M \mathbf{1}^T \mathbf{v} \\ &\text{subject to}& - \mathbf{u} - \mathbf{v} \preceq \mathbf{y} - \mathbf{X} \beta \preceq \mathbf{u} + \mathbf{v} \\ & & \mathbf{0} \preceq \mathbf{u} \preceq M \mathbf{1}, \mathbf{v} \succeq \mathbf{0} \end{eqnarray*} in $\mathbf{u}, \mathbf{v} \in \mathbb{R}^n$ and $\beta \in \mathbb{R}^p$. Hint: write $|r_i| = (|r_i| \wedge M) + (|r_i| - M)_+ = u_i + v_i$.

- Example: Support vector machines (SVM). In two-class classification problems, we are given training data $(\mathbf{x}_i, y_i)$, $i=1,\ldots,n$, where $\mathbf{x}_i \in \mathbb{R}^n$ are feature vector and $y_i \in \{-1, 1\}$ are class labels. Support vector machine solves the optimization problem \begin{eqnarray*} &\text{minimize}& \sum_{i=1}^n \left[ 1 - y_i \left( \beta_0 + \sum_{j=1}^p x_{ij} \beta_j \right) \right]_+ + \lambda \|\beta\|_2^2, \end{eqnarray*} where $\lambda \ge 0$ is a tuning parameters. This is a QP.